The brand we were working with.
Miabella is a 16-year-old multi-instrumentalist and the frontwoman of the Belfast band that bears her name. She holds Trinity College London Distinctions in Rock & Pop guitar (Grade 8) and a Merit in piano (Grade 7), plays an 18-string double-neck, and fronts a four-piece live band that performs at weddings, private events, and her own concept shows — The Electric Age (40 years of rock evolution) and Baroque to Rock (the line from classical to grunge across 400 years).
The site we built for her lives at miabella.uk. It is static HTML — JSON-driven, Git-versioned, served from Cloudflare's edge. It costs nothing per month to host. It scores 100/100/100 on Accessibility, Best Practices and SEO in Google PageSpeed Insights, and 93 on Performance.
Those numbers are real, and they're useful as a baseline. They are not the interesting part of this case study.
The interesting part is what the AI providers — Google's Gemini, OpenAI's web-grounded models, Google's AI Overview surface — now say about her, unprompted, when a real customer asks.
Three layers, built in from the start.
Foundation: structured data as load-bearing infrastructure.
Most websites bolt schema.org markup on as a checkbox at the end of a build. We built it in from the start as the architectural spine. A Person entity at miabella.uk/#mia carries her legal name, alternative names, four EducationalOccupationalCredential blocks with Ofqual reference numbers and credential.net verification URLs, occupation, citizenship, birth date, and a 16-entry sameAs array linking to Wikidata, Wikimedia Commons, MusicBrainz, BandsInTown, setlist.fm, and her own social profiles. A MusicGroup entity at #musicgroup carries the full band lineup with each member's profile URLs, genre tags, founding location, an aggregateRating of 5.0/5 from 10 reviews, and ten individual Review blocks with named authors, organisations where applicable, and dates. Every chronicles article and every event reuses these entities by @id reference rather than redeclaring them.
This is not normal SEO. This is entity-resolution work — telling Google, Wikidata, MusicBrainz, and any other system that catalogues musicians: this is one specific person, here is her verified credential trail, here are the other systems that already know her. Without this, search engines see a website. With it, they see a recognised entity with a Knowledge Graph node.
Layer two: long-form articulated content as AI grounding material.
The chronicles section of the site is a deliberately structured collection of essays. They are not blog posts in the traditional content-marketing sense. Each one fills a specific gap that an AI model would otherwise improvise about. Why we're not yet on Spotify articulates a counter-cultural choice about streaming. A name is a name articulates the relationship between the singer's legal name, the band's name, and the disambiguation against Mia Bella (Canadian artist) and Nina Nesbitt (Scottish singer). Why tribute bands matter articulates the artistic position behind the cover repertoire. Music is not a privilege articulates the mission. Each one gives the model a citable answer for a question someone might plausibly ask, in the brand's own voice, with specific phrasing the model can quote.
Layer three: instrumented measurement.
The site is connected to a multi-provider AI-visibility detector that runs scheduled scans across OpenAI's web-grounded responses, Google's Gemini with grounding, and Google's AI Overview surface (via SerpApi). For each scan, it captures the model's response text, the cited sources, and three position metrics: where the brand appears in the text, where it appears in any recommendation list, and where it appears in the citation list. New issues are written when the brand fails to surface for a high-priority query; resolutions are written when the issue is no longer re-seen on a subsequent scan.
That instrumentation is what makes the rest of this case study possible. Without it, the findings below would be anecdote. With it, they are measurement.
A 16-year-old indie musician with a Google Knowledge Panel.
Search Google for miabella musician. The result panel on the right of the search results page is the Knowledge Panel. It carries her name, the descriptor Irish singer, and her birth date — 16 October 2009. That birth date is rendered from the Person.birthDate field in her own website's JSON-LD.
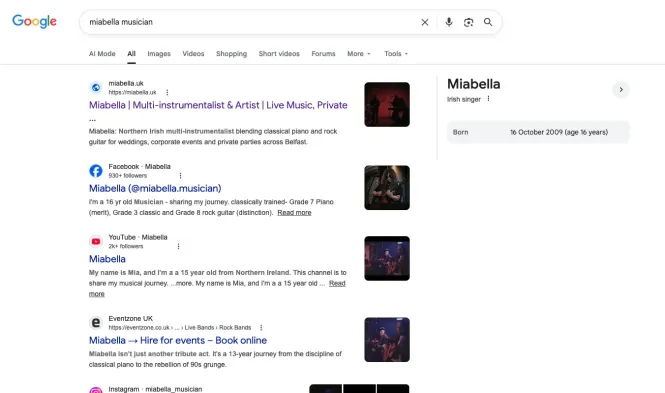
Knowledge Panels are not automatically granted. Google decides who qualifies based on entity recognition — the cumulative signal that this is one specific, identifiable, real-world entity that matches a stable identity across multiple authoritative sources. Most artists with substantially larger audiences do not have Knowledge Panels, because Google does not recognise them as resolved entities.
She has one because the architecture is doing the work.
The 16-entry sameAs array on her Person entity links Wikidata Q138857029, Wikimedia Commons, MusicBrainz, BandsInTown, setlist.fm, encore, skiddle, eventbrite, eventzone, and the credential.net verification URLs for each of her four Trinity certificates. The credential.net URLs are unusual — they are third-party-verifiable, Ofqual-regulated credential records, not marketing claims. Anyone can click those URLs and see the certificate. So can a model, when grounding a claim about her credentials.
The MusicGroup entity adds 13 more sameAs links and a named member list with each member's individual profile URLs. The aggregate of these signals — Wikidata recognition, MusicBrainz catalogue entry, verified credentials, named member list, ten reviews from named authors — adds up to enough for Google to render a Knowledge Panel.
This is how structured data is supposed to work. It almost never does, because most agencies treat it as a checkbox. Done as load-bearing architecture, it produces visible, recognisable proof: a Knowledge Panel for a 16-year-old indie musician.
Verbatim phrase pickup, in answer to a question that wasn't asked.
On the 1st of May 2026, Miabella published an essay on her chronicles section titled Why we're not yet on Spotify. The essay articulates her position on streaming — that she is deliberately building a live audience first, that recordings made now would be a souvenir for an audience that doesn't yet exist, and that:
So what are we doing instead? We're playing rooms. Real, physical rooms with real people in them.
— miabella.uk/chronicles/why-not-on-spotify · published 2026-05-01 09:00 BST
Two days later, a user asked Gemini miabella singer, then followed up with UK. Gemini's answer was a summary of who she is — multi-instrumentalist, Northern Ireland, the Trinity grades, the band members, the show concepts, the upcoming gigs. And, unprompted, in the Online Presence section of Gemini's response, this:
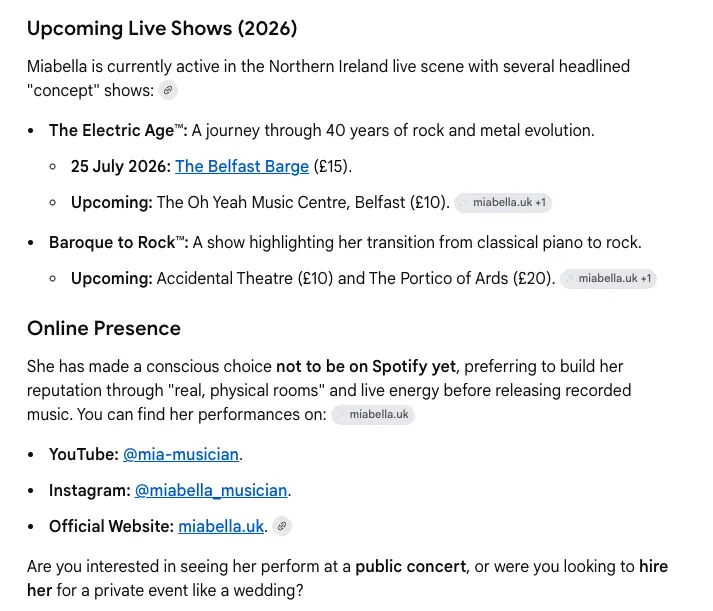
The phrase "real, physical rooms" appears in quotation marks in Gemini's own output. That is not summary. That is verbatim quotation, with attribution to miabella.uk.
The query that triggered it was not about streaming. miabella singer / UK is an identity-level question. The model chose to inject the Spotify positioning into the answer because the article gave it articulated material on that aspect of the brand. Without the article, the model would have either omitted streaming entirely or invented a generic available on all major platforms line. With the article, the user gets the artist's actual positioning, in her own framing.
This matters because it generalises. Long-form articulated content gets pulled into any query where the model needs descriptive substance about the brand — not just queries that match the article's topic. An essay about Spotify positioning informs answers to who is this artist. An essay about pop versus grunge informs answers to what kind of music does she play. An essay about why the band is named what it is informs answers to what is her real name. Each article extends the model's articulated grounding for the entire brand, not just for the topic the article is ostensibly about.
For a business that's currently invisible to AI summaries — or worse, being summarised by inventions — every gap in articulated content is a fabrication waiting to happen. Every article that fills a gap is a fabrication eliminated. The maths is straightforward.
Three providers. Three different grounding strategies. One brand needs all three.
The same brand looks meaningfully different across providers. Running the multi-provider detector against high-priority queries about Miabella reveals a pattern that holds across all the sites we have instrumented.
OpenAI's web-grounded responses preferentially cite Google Maps Place URLs.
When asked about a venue or a service business, OpenAI grounds heavily on Maps. For a band like Miabella, this means Eventzone, Skiddle, and her Google Business Profile (configured for live-events bookings) carry disproportionate weight. Optimising for OpenAI grounding looks a lot like vendor optimisation: complete profile, accurate hours, structured event listings, photos that match the business description.
Gemini preferentially cites direct site URLs and community sites.
The chronicles articles, Reddit discussions, Quora answers, and music-industry directories show up most often in Gemini's grounding panel. Optimising for Gemini grounding looks like content depth: long-form articulated essays on the brand's own site, plus presence on community surfaces where readers discuss the genre, the venue, the question.
SerpApi / Google AI Overview cites adjacent-intent surfaces.
For queries with a wedding-vendor framing — grunge wedding band Belfast, alt-rock wedding music Northern Ireland — Google's AI Overview tends to cite wedding-photographer portfolios, planning blogs, and venue review pages. Neither Maps surfaces nor music-industry surfaces dominate. Optimising for AI Overview grounding looks like cross-vendor referral work: photographer relationships, venue partnerships, planner-network presence.
Three providers. Three distinct grounding strategies. One brand needs all three to be fully visible. Most agencies are still selling a single-strategy SEO play that worked in 2018. What ranks in Google's blue links is increasingly secondary — what gets cited in the AI summary above the blue links is the new battleground, and the surface mix is provider-specific.
48 to 72 hours from publish to AI grounding.
The Spotify essay was published at 09:00 BST on the 1st of May 2026. The Gemini quotation was observed on the 3rd of May 2026. That's roughly 48 hours. We have observed the same latency across multiple chronicles articles and across other connected sites we instrument: long-form content reliably reaches AI-search surfaces within 48 to 72 hours of publishing.
That predictability matters. Most SEO interventions take weeks to months to show measurable effect; most paid-media interventions show effect within hours. AI-grounding interventions sit between the two — slower than ads, dramatically faster than traditional SEO, and within the same business week as publishing. Publish on Monday, see the model citing it by Wednesday or Thursday.
That converts content writing from a vague long-term bet into a near-term measurable lever. Write the article, schedule the publish, run the detector 72 hours later, see what changed. If the article didn't surface, we know within the week and can iterate. We don't wait three months to find out it failed.
This is the underrated mechanic. The whole point of measurement is to shorten the iteration loop. AI grounding is currently the only content channel where the iteration loop is short enough to actually optimise for.
The Lighthouse score, while we're here.
Useful to mention because every WordPress site we replace has a Lighthouse problem. Not the headline, because the AI grounding work above is the actually differentiated bit. But for completeness:
For comparison: the typical mid-budget WordPress site we audit scores between 28 and 55 on Performance, with LCP above 4 seconds and ongoing hosting costs of £25–£120 per month. Same content. Different stack.